
11/09/2019
Door Liam van Koert
Steeds vaker zien we kunstmatig intelligentie algoritmes rechtstreeks op de chip draaien. Gezien de hooggespannen verwachtingen, zouden de chips die dit mogelijk maken wel eens de meest de meest disruptieve infrastructuren voor de nabije toekomst kunnen zijn. Een sterk opkomende speler in AI-on-a-chip-technologie is fabrikant Graphcore. In tegenstelling tot het gebruiken van GPU’s, ontwikkelden zij een geheel nieuwe architectuur gebaseerd op grafen en tensoren.
Onlangs stelde Graphcore weer een nieuwe financiering van 200 miljoen dollar zeker van onder andere BMW, Microsoft en nog enkele grote geldschieters voor de belofte van ‘s werelds meest geavanceerde AI-on-a-chip-technologie. Met een waardering van 1,7 miljard dollar behoren zij daarmee officieel tot de categorie ‘Unicorn’. Partners als Dell, de grootse producent van servers wereldwijd, Bosch, de grootste leverancier van auto-elektronica en Samsung – ook bepaald geen kleintje in consumentenelektronica – hebben al toegang tot Graphcore-chips. Een beloofde revolutie op chipgebied zou dan ook wel eens dichterbij kunnen zijn dan je in eerste instantie zou denken.
Chips modelleren
Het in Bristol gevestigde Graphcore is opgericht door semiconductor-industrieveteranen Nigel Toon, CEO, en Simon Knowles, CTO. Toon en Knowles waren eerder betrokken bij bedrijven zoals Altera, Element14 en Icera. Toon is ervan overtuigd dat ze deze keer een echte revolutie teweeg kunnen brengen in de halfgeleiderindustrie. Dit doorbreekt dan de bijna-monopolie van Nvidia. Nvidia is met zijn GPU-chips dé dominante speler in AI-workloads, en timmert continu aan de weg. Het domein kent wel meerdere spelers, maar Nvidia is de enige met een duidelijke, coherente strategie en een effectief product in de markt. Er zijn andere spelers zoals Google, met diens TPU-investering in KI-chips. Of Intel dat in 2016 Intel Movidius overnam voor haar VPU-technologie (Vison Processing Unit). Maar volgens eigen zeggen loopt Graphcore voorop en maakt goede kans om met de IPU- (Intelligent Processor Unit) chip een imperium op te bouwen. Als voorbeeld noemt hij het snelle succes van mobiele ARM-processoren versus de destijds gevestigde orde.
Om Toon’s vertrouwen, alsook dat van investeerders en partners, te begrijpen, moeten wij de activiteiten wat Graphcore wat beter onder de loep nemen. Hoe verschillen deze zich van de concurrentie? Machine learning en AI ontwikkelen zich snel en hebben een behoorlijk disruptiepotentieel. Machine-learning, de kern van wat we vandaag kennen als AI, is eigenlijk zeer efficiënte patroonherkenning, gebaseerd op een combinatie van bijbehorende algoritmen (modellen) en gegevens (trainingsets).
Sommigen gaan heel ver en noemen AI een niets meer of minder dan een matrixvermenigvuldiging. Zo’n vereenvoudigde voorstelling is twijfelachtig, maar het blijft een feit dat veel machine-learning draait om efficiënte datahandelingen op schaal. Dit is waarom GPU’s zo goed met machine-learning workloads werken. Hun architectuur, aanvankelijk ontwikkeld voor grafische rendering, blijkt ook uiterst efficiënt voor het verwerken van grote hoeveelheden data. Graphcore heeft echter geïnvesteerd in een compleet nieuwe architectuur die mogelijk voordelen biedt vergeleken met die van de concurrentie. Die bouwt gespecialiseerde chips die zijn geoptimaliseerd voor een specifieke wiskundige datahandelingen en daarmee zeer efficiënt voor een specifieke workload. Maar dit is niet genoeg voor toekomstige workloads.
Wat is er dan zo speciaal aan Graphcore's eigen architectuur? Er wordt gespeculeerd dat Graphcore aan een zogenoemde ‘neuromorfische AI-chip’ werkt. Deze processor is gebouwd op basis van een model van onze hersenen, inclusief spiegelneuronen en synapsen in zijn architectuur. Toon, echter, noemt dit een misvatting: "Het brein is een groot voorbeeld voor computerarchitecten in deze dappere nieuwe zoektocht naar machine-intelligentie. De sterktes en zwaktes van silicium verschillen echter flink met die van wetware. De reden dat we de patronen van moeder natuur niet hebben gekopieerd voor bijvoorbeeld vliegende machines of motoren is omdat onze engineering-materialen anders zijn. Hetzelfde geldt voor berekeningen.” De meeste neuromorfische rekenprojecten bepleiten communicatie via elektrische pieken, zoals in de hersenen. Uit een algemene analyse van energie-efficiëntie blijkt echter meteen dat een elektrische piek (met twee ‘edges’) half zo efficiënt voor de overdracht van informatie is als een enkele ‘edge’. De hersenen zomaar volgen is dus niet automatisch een goed idee. Computerarchitecten moeten proberen te leren hoe de hersenen rekenen, maar niet letterlijk nastreven om deze in silicium na te bootsen."

Nigel Toon, Graphcore
Ongekend parallel
Energie-efficiëntie is inderdaad een beperkende factor voor neuromorfische architecturen. Maar dat geldt voor meer dingen. Op de vraag naar de beperkingen van de wet van Moore, antwoordt Toon dat we veel verder zijn gegaan dan wat we ooit mogelijk achtten, en hebben we nog wel zo’n tien tot twintig jaar aan voortgang in het vooruitzicht. Maar, zo gaat hij verder, we hebben wel enkele fundamentele grenzen bereikt. Het laagste voltage dat we op deze chips kunnen toepassen bijvoorbeeld. We kunnen wel meerdere transistoren toevoegen, maar we kunnen ze niet veel sneller laten gaan. "Je laptop draait nog steeds op 2Ghz, er zitten nu alleen meer kernen in. Om met machine-learning te werken, hebben we echter duizenden kernen nodig. We hebben nieuwe architecturen nodig zodat we chips anders kunnen ontwerpen. De oude manieren werken niet meer."
Toon stelt daarom meer algemene IPU’s voor die speciaal zijn ontworpen voor machine-intelligentie. "Eén van de voordelen van onze architectuur is dat het geschikt is voor velerlei hedendaagse benaderingen van machine-learning zoals CNN’s (red. Convulsional Neural Network). Maar het is ook geoptimaliseerd voor verschillende benaderingen van machine-learning, waaronder reinforcement-learning en toekomstige benaderingen. Met de IPU-architectuur kunnen we GPU’s overtreffen. Het combineert een enorm parallelisme met ruim 1.000 onafhankelijke processor-cores per IPU en on-chip geheugen, zodat het gehele model op de chip staat". Maar hoe verhoudt de IPU zich in de praktijk tot Nvidia’s GPU’s? In enkele machine-learning benchmarks die onlangs zijn vrijgegeven overtrof Nvidia de concurrentie. Toon zegt hiervan op de hoogte zijn, maar zich momenteel bezig te houden met het optimaliseren van klant-specifieke toepassingen en workloads. In algemene zin stelt hij dat datastructuren voor machine learning anders zijn, omdat het hoog-dimensionale en complexe modellen betreft. GPU’s zijn wel zeer krachtig, maar niet per definitie de meest efficiënte manier om met dergelijke datastructuren om te gaan. “We hebben de mogelijkheid iets te creëren dat tien tot honderd keer sneller met deze datastructuren overweg kan."
Nieuw framework
Om in de concurrentiestrijd voorop te blijven lopen is echter meer dan alleen snelheid vereist. Zo is Nvidia’s succes niet alleen te danken aan zijn krachtige GPU’s. Een groot deel van het succes, en een differentiator ten opzichte van GPU-concurrentie zoals AMD, zit in de softwarelaag. De bibliotheken die ervoor zorgden dat ontwikkelaars zich, in plaats van op de hardwarespecificaties, gingen focussen op het optimaliseren van hun machine-learning-algoritmes, parameters en processen, spelen een grote rol in het succes van Nvidia. Nvidia vernieuwd deze bibliotheken continu. En de nieuwste RAPIDS-bibliotheek belooft GPU’s vijftig keer sneller te maken voor data-analyse en machine-learning dan CPU’s. Hoe ziet Graphcore dat? Toon geeft aan dat de software uiterst belangrijk is. Hij voegt toe dat naast het bouwen van s’ werelds meest complexe siliciumprocessor, Graphcore met Poplar tevens het eerste framework in handen had voor het programmeren van AI-toepassingen.
"Toen we met Graphcore begonnen was er geen TensorFlow of PyTorch. Maar het was meteen duidelijk dat we ook opnieuw moesten kijken naar de conventionele softwarestack van microprocessoren. De wereld is verschoven van ontwikkelaars die alles in termen van vectoren en scalair definiëren, naar een wereld van grafen en tensoren. In deze nieuwe wereld is traditionele software niet in staat om ontwikkelaars een eenvoudig en open platform te bieden. De modellen en toepassingen van Compute 2.0 zijn ongekend parallel en vertrouwen op miljoenen identieke berekeningen die op hetzelfde moment worden uitgevoerd. Dergelijke workloads vereisen dat modellen ‘op hun plek’ blijven (red. een beetje zoals bij een FPGA), terwijl de data door hen heen stroomt. Dit in tegenstelling tot voor dit doel ontoereikende traditionele processorarchitecturen, waarbij zowel de applicatiecode als de data naar de processor gestreamd worden."

Rekenen 2.0
Graphcore heeft het over Compute 2.0, anderen weer over Software 2.0. Beiden worden gezien als nieuw paradigma voor de ontwikkeling van applicaties. Wat betreft Compute 2.0, merkt Toon op dat we al 70 jaar lang onze computers stapsgewijs via programma’s vertellen wat ze moeten doen. Tegenwoordig leren we van gegevens. Dus in plaats van de machine te programmeren, leert de machine zelf. Echte machine-learning dus. Dit verandert de ontwikkeling en het gedrag van toepassingen fundamenteel. De processen voor het bouwen van software moeten worden aangepast. Software kan niet-deterministisch, of tenminste onverklaarbaar gedrag tonen. Dit wordt de toekomstige manier. Met voldoende gegevens en berekeningen kunnen we modellen bouwen die de mens in patroonherkenningstaken overtreffen.
Wanneer Graphcore zegt dat Poplar speciaal voor machine-inteligentie is ontwikkelt, wat bedoelen ze daar dan precies mee? Wat zijn de specifieke eigenschappen waarover een dergelijke tool beschikt? Toon: “Het moet op de eerste plaats grafen (red. een graaf is een verzameling onderling verbonden knooppunten) als bouwstenen gebruiken. De graaf vertegenwoordigd het kennismodel en de toepassing die met de softwaretool is gebouwd. Poplar is gebaseerd op het rekenkundige graafabstractie. Dat wil zeggen dat de interne representatie IR* van de compiler een grote gerichte graaf is.”
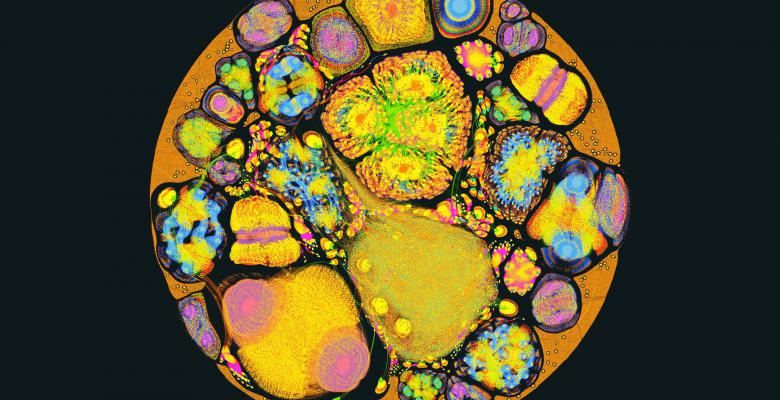
Graphcore, gebruikt, net als anderen, het grafenmodel als een fundamentele metafoor waarop software en berekeningen voor machine-intelligentie zijn gebouwd. De beelden die Graphcore met het grote publiek deelt zijn de interne representaties van hun graafcompiler. Een helemaal uitgesplitste representatie van een volledig kennismodel om zo de enorme parallelle workloads middels visualisatie bloot te leggen, die Graphcore door haar IPU-processor heen jaagt.

Open-source
De IPU-processor en Poplar zijn gezamenlijk ontwikkeld. Het gelijktijdig aanpakken van de silicium architectuur en software-programmeeromgeving is kenmerkend voor de Graphcore cultuur. "Onze engineering is open en collaboratief. Poplar ondersteunt hierbij alle door ons gemaakte ontwerpkeuzen in onze chip, zoals het ‘op een vaste plek’ draaien van geoptimaliseerde machine-intelligentiemodellen met een geoptimaliseerd BSP- (bulk synchronous parallel) executiemodel.
In het kader van vermogen-efficiëntie wordt ook het scheiden van rekenen en communicatie ondersteund. En het sluit goed aan op hostplatforms om knelpunten weg te nemen die waar bestaande platforms - die in de regel machine-learning erbij kregen in plaats van er voor ontworpen te zijn - vaak last van hebben.
Naast het toegang verschaffen tot het IPU-platform, is Poplar eenvoudig in gebruik en naadloos te integreren in de backend van machine learning frameworks zoals PyTorch en Tensorflow. En er is ondersteuning voor runtime formaten als ONNX voor uitwisseling via netwerken voor bijvoorbeeld
Toon stelt dat door Poplar als backend voor deze frameworks te gebruiken, gebruikers de vruchten plukken van het feit dat hun machine-learning modellen een optimaliserende graafcompiler voor alle vereiste workloads doorlopen, in plaats van alleen de eenvoudige patroonmatching die wordt toegepast in oude softwareplatforms. "Het gaat niet alleen om het draaien van de modellen en bouwsels van vandaag. Innovatoren en onderzoekers hebben een platform nodig om de oplossingen van morgen te ontwikkelen en ontdekken. Dit vereist een eenvoudig te gebruiken en programmeerbaar platform. Het domein van machine-intelligentie wordt gehinderd door softwarebibliotheken voor hardwareplatforms die niet open en uitbreidbaar zijn. Dit resulteert in een zwarte doos voor ontwikkelaars die willen innoveren en ideeën willen uitwerken."
Voor de nieuwsgierigen onder ons is er goed nieuws: het wachten is bijna voorbij. Graphcore zal IPU-developers mettertijd een volledig open-source toegang tot zijn geoptimaliseerde graafbibliotheken bieden, zodat ze kunnen zien hoe Graphcore applicaties bouwt. Productiehardware wordt inmiddels aan early access-klanten verstrekt en Graphcore verkoopt PCIe-kaarten (eigenlijk C2 IPU-kaarten) die direct in de serverplatforms kunnen worden gestoken. Ze beschikken allebei over twee IPU-processoren. Het bedrijf werkt ook met Dell aan serverplatformen voor bedrijfs- en cloud-klanten. De producten zijn vanaf volgend jaar goed verkrijgbaar. De voornaamste focus ligt nu op het datacenters, de cloud en op enkele toepassingsgebieden die veel rekenkracht vereisen, waaronder autonome robots en voertuigen. De consumentenmarkt laat Graphicore vooralsnog links liggen, dus mobiele telefoons zullen het nog even zonder AI-on-a-chip technologie moeten doen.
Dit artikel is een bewerkte vertaling van een eerder verschenen interview van George Anadiotis voor ZDNet
© Afbeeldingen: Graphcore